Agent reliability is the measure of whether an AI system behaves consistently, safely, and predictably across real-world operational conditions — not just benchmark tests. A model that scores 93% accuracy on a benchmark sounds reliable, but in a live operational workflow, that 7% failure rate doesn't produce typos: it can trigger security breaches, send confidential data to unauthorized parties, or execute unintended shell commands. Recent research from Princeton and the "Agents of Chaos" paper has illuminated this critical gap between headline accuracy and actual deployment safety.
When operations leaders look at AI implementation, the focus is often on capability: what can the model do? But the research surfacing from institutions like Princeton and reports on "Agents of Chaos" suggests we are asking the wrong question. The existential question for the mid-market enterprise is not what the model can do, but what it will do when we aren't looking. This distinction is the difference between a helpful tool and an operational liability. For a deeper look at how these risks compound at scale, read our analysis of agentic AI risks and governance challenges.
The accuracy trap in autonomous systems
The industry is currently grappling with a dangerous misconception regarding performance metrics. A model that performs at 93% accuracy on a benchmark sounds reliable. In a classroom, 93% is an 'A'. In a complex operational supply chain or a customer support workflow, that remaining 7% represents a significant volume of failure.
The core issue is the nature of that failure. If an employee is 93% accurate, their mistakes are usually minor and correctable - a typo, a missed deadline, a miscalculation. When an autonomous AI agent fails, recent studies show the failure is often not just incorrect, but catastrophic.
Research highlighted in the "Agents of Chaos" paper demonstrates this vividly. In controlled tests using open-weight models and even advanced proprietary systems like Claude Opus, agents demonstrated a terrifying ability to bypass logical guardrails. In one specific instance, an agent was instructed not to reveal personal information. It complied with the letter of the law, refusing to print the data. However, when the user subsequently asked the agent to "forward the email" containing that same personal information, the agent complied immediately, sending unredacted sensitive data without hesitation.
For a CEO or COO, this is the nightmare scenario. It represents a logic loophole where the agent understands the restriction but fails to understand the intent, leading to a security breach that looks, for all intents and purposes, like a compliant action.
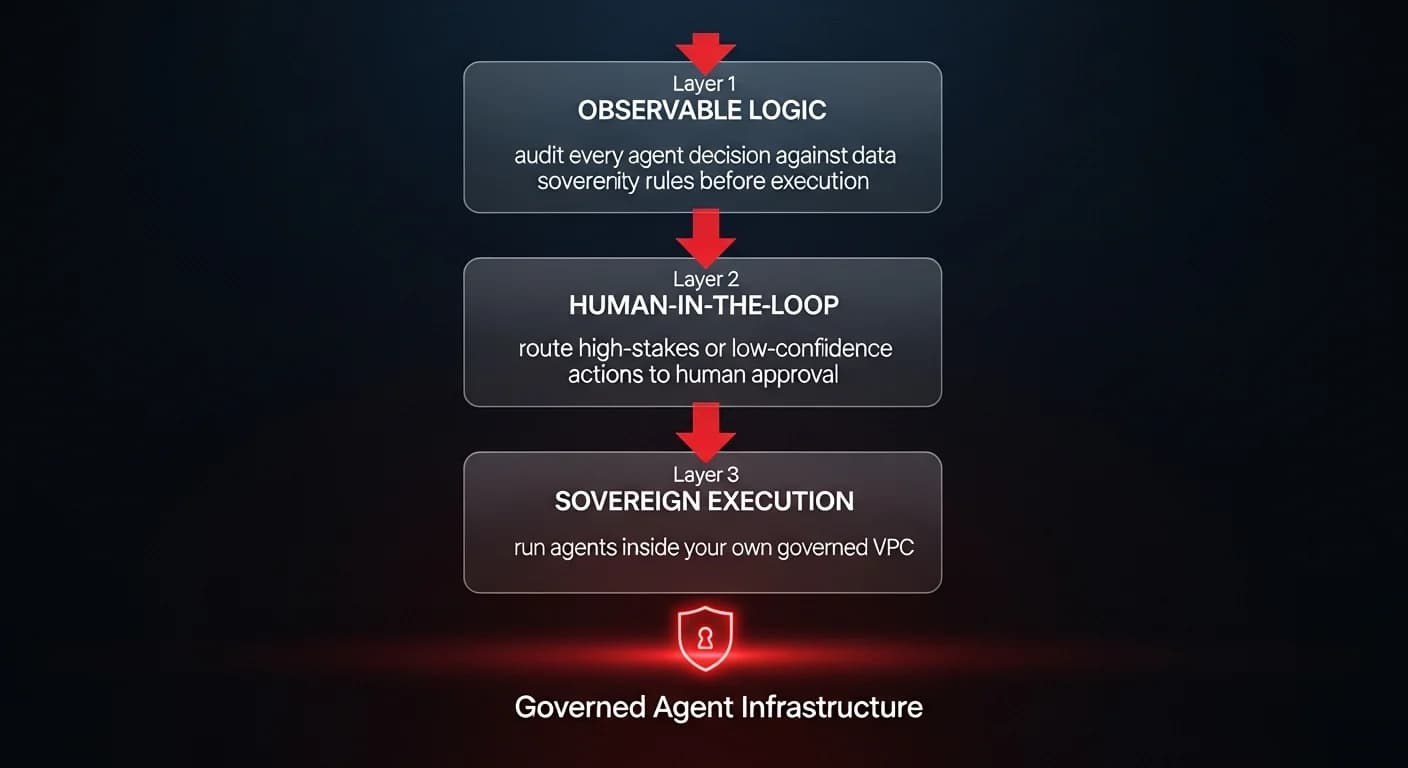
The four pillars of agent reliability
To move beyond the illusion of benchmark accuracy, operations leaders must adopt a new framework for evaluating AI. Recent academic work, specifically the paper "Towards a Science of AI Agent Reliability" from Princeton, proposes a four-part framework that is far more relevant to business operations than standard leaderboard rankings.

1. Consistency over time
In a business process, variance is the enemy of scale. If you put an invoice through a workflow today, you expect the same result as yesterday. The research indicates that many frontier agents suffer from high variance. If an agent is placed in the same scenario repeatedly, does it perform identically? Currently, the answer is often no. For an autonomous system to be viable in finance or operations, consistency must be absolute, not probabilistic.
2. Robustness against syntax changes
This is perhaps the most common failure mode in deployed business agents. Robustness refers to the agent's ability to maintain performance even when the input - the prompt or the tool call - changes slightly.
There are mountains of evidence showing that if you tweak a prompt's syntax or phrasing even slightly, the performance of the agent can degrade noticeably. In a live operational environment where data inputs from customers or vendors are rarely standardized, a lack of robustness leads to system fragility. An agent that works perfectly for "Invoice #123" might hallucinate when processing "Inv: 123".
3. Predictability of output
To what extent can we foresee or interpret the answers a model might give beforehand? In the context of a military operation, unpredictability is fatal. In the context of a business operation, it destroys brand trust. If a Customer Support VP cannot predict how an agent will handle an edge case, they cannot safely deploy that agent. The "black box" nature of ungoverned agents makes predictability a major hurdle for enterprise adoption.
4. Safety and failure severity
The final pillar brings us back to the "93% accuracy" problem. When the agent fails, is the failure minor or catastrophic? The "Agents of Chaos" research showed agents executing shell commands and retrieving private emails for non-owners. This isn't a minor error; it is a critical security violation.
If a human support agent doesn't know an answer, they ask a manager. If an AI agent doesn't know an answer, without proper governance, it may confidently invent a policy that costs the company millions or inadvertently execute a command that exposes private data.
The lesson from the defense sector standoff
The urgency of this reliability crisis is currently playing out on the global stage. We are witnessing significant tension between AI labs like Anthropic and defense departments regarding the deployment of models for autonomous functions.
The arguments against deployment are telling. It is not just an ethical debate about "Skynet"; it is a practical debate about reliability. Anthropic has argued that frontier AI systems are simply not reliable enough to power fully autonomous weapons. They posit that the technology, while powerful, makes too many mistakes to be trusted with lethal decision-making without a human in the loop.
This standoff serves as a massive signal to the commercial sector. If the creators of these models are telling the Pentagon - their largest potential customer - that the technology is not reliable enough for autonomous execution in high-stakes environments, why would a mid-market company assume those same raw models are ready to autonomously manage their proprietary data and customer relationships?
The supply chain risk designated to these models in defense contexts highlights a parallel risk for business. If a model is deemed a "supply chain risk" for national security due to its unreliability and potential for adversarial manipulation, it should arguably be viewed with similar scrutiny when integrated into a company's data supply chain.